맵 리듀스는 여러 노드에 테스크를 분배하는 방법이다. 각 노드 프로세스 데이터는 가능한 경우, 해당 노드에 저장된다.
맵 리듀스 테스크는 맵(map) 과 리듀스(reduce)로 구성된다.
쉬운 예시로는 Fork-Join 풀인데, 이 풀은 큰 업무를 작은 업무 단위로 쪼개고, 그것을 각기 다른 cpu에서 병렬로 실행한 후 결과를 취합하는 방식이다. 아래 이미지를 통해 fork-join 에 대해서 간략하게 이해할 수 있으니 참고.

맵 리듀스는 위 fork-join 풀처럼 큰 작업들을 fork 로 분할해서 처리한 뒤에 다시 join 해서 결과물을 만드는 방식인 것이다. 하둡은 계산시, 큰 파일을 블럭 단위로 나누고 모든 블럭은 같은 Map 작업을 수행후 다시 Reduce 작업을 수행하게 된다.
- Map( 맵 )
데이터를 담아두는 자료 구조 중의 하나. Key 와 Value 라는 두개의 값으로 이루어져 있는 딕셔너리 형태이다.
- Reduce(리듀스)
맵을 정리해 나가는(줄여나가는) 방법이다. key 를 기준으로 (같은 key 값을 가지고 있는 맵들의) 개수를 세거나, 같은 key를 기준으로 value 들을 모두 더하거나, 평균을 내거나 하는 것들이다.
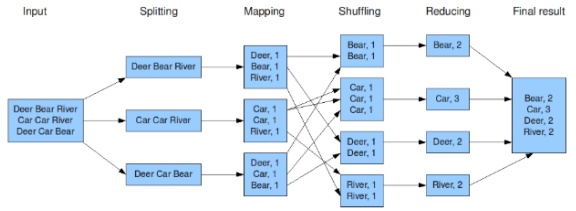
아래의 이미지는 맵리듀스에 대한 프로세스를 이해하는 데 도움이 될것 같다.
- MapReduce Job) : Client 수행 작업 단위
클라이언트가 수행하려는 작업 단위로서 입력 데이터, 맵리듀스 프로그램, 설정 정보로 구성되며, 하둡은 Job 를 Map 테스크와 Reduce 테스크로 작업을 나누어서 실행하는데, 이 때 Job 실행 과정을 '제어'해주는 노드이다
--> Job Tracker(잡 트래커) : 테스크 트래커가 수행할 Task 스케쥴링, 시스템 전체 수행을 조절
--> Task Tracker(테스크 트래커) : Task 수행하고, 잡 트래커에게 전체 경과 보고.

맵리듀스 관련 참고 링크
[하둡] 맵리듀스(MapReduce) 이해하기
맵리듀스는 여러 노드에 태스크를 분배하는 방법으로 각 노드 프로세스 데이터는 가능한 경우, 해당 노드에 저장됩니다. 맵리듀스 태스크는 맵(Map)과 리듀스(Reduce) 총 두단계로 구성됩니다. 간단한 예를 들면 f..
12bme.tistory.com
맵/리듀스 (Map/Reduce) 이해하기
빅데이터를 접하기 시작하면서 자주듣게 되는 용어가 있습니다. 맵/리듀스 라는 용어인데요, MR이라고도 많이 쓰구요, 빅데이터 처리에는 늘 맵리듀스 개념이 들어가죠. 그럼, 빅데이터 처리의 기본이되는 맵리듀..
cskstory.tistory.com
https://over153cm.tistory.com/entry/%EB%A7%B5%EB%A6%AC%EB%93%80%EC%8A%A4MapReduce%EB%9E%80-1
맵리듀스(MapReduce)란? -1-
맵리듀스(MapReduce)란? : 대용량 데이터를 처리를 위한 분산 프로그래밍 모델 - 구글에서 2004년 발표한 소프트웨어 프레임워크 - 타고난 병행성(병렬 처리 지원)을 내포 - 누구든지 임의로 활용할 수 있는 충분..
over153cm.tistory.com
'Data Engineering > HDFS' 카테고리의 다른 글
| - hive : SerDe (서데) 란? (0) | 2020.03.31 |
|---|---|
| - hive : ORC 포멧 (0) | 2020.03.31 |
| hadoop: 하둡 명령어 1 (0) | 2020.03.24 |
| 프로젝트 주요 개념02 - 애드혹 분석(Ad-hoc) (0) | 2020.03.11 |
| 설치 사전 작업 : open JDK vs oracle JDK (0) | 2020.03.10 |