지금 개인적으로 진행하고 있는 파이썬 사이드 프로젝트들은 꽤 간단한 편이다.
생각보다는 쉬워서 건너뒤고 다른 것을 해볼까 싶기도 하지만,
잠깐 잠깐 공부하고, 다시 기초를 다진다는 생각으로 하면서 점차 어려운 프로젝트로 발전시켜 나가면 좋을 것 같다
그런 의미에서 오늘은 간단한 email slicer 를 만들었다.
이메일을 입력하면 도메인 주소와 아이디를 분류해주는 코드이다.
처음에는 그저 어려운줄 알았지만, 막상 자료를 찾아보니 꽤 쉬웠다.
emails = input("이메일을 입력해주세요!").strip()
# -> strip()를 써준 이유는 input 입력과정에서
# 공백이 만들어질 수 있기에 이를 방지해주고자 썻다.
# 다른 프로젝트에서 input 을 사용할 때 위 방법을 응용하면 공백방지에 도움이 될 것 같다.
# 아이디 : snepbnt404
ids = emails[0:emails.index('@')]
print(ids)
# 도메인 : naver.com
domains = emails[emails.index('@')+1:]
print(domains)
# 사이트 : naver
sites = domains[:domains.index('.')]
print(sites)
print("아이디는 {0} 이며, 도메인 주소는 {1} 그리고 사이트는 {2} 입니다".format(ids,domains, sites))프로젝트 고려사항
1. 리스트의 index( ) 함수의 특성을 잘 활용해야 한다.
index( ) 의 경우에는 입력한 [문자열] 의 수량을 알려주는 함수이다(틀릴수도 있다)
그러기에 문자열의 갯수를 카운팅할 때 가장 차음의 [문자열]을 카운팅하기에
인덱싱을 할 때 써주면, 가장 처음의 [문자열]까지 또는 에서 인덱싱을 할 수 있다.
2. 도메인 주소에서 사이트의 명칭을 뽑아내어 어떤 사이트 소속인지 알아야 한다.
2번을 위해서 index( ) 의 특성을 이용했다. ' @ ' 앞에 ' . ' 이 붙어 있으면 그 위치로 인덱싱이 되어버리기 때문에
도메인 주소에서 원하는 사이트를 인덱싱하기가 힘들어진다. 그래서 따로 domains 라는 함수를 만들어주었다.
주의사항
사이트의 경우는 예외가 있을 수 있다. 예를 들면 gmail, hanmail 의 경우를 들 수 있겠는 데 이러한 상황에서는 따로 사이트를 추출하는 게 틀릴 수 있으니 참고 해야할 것 같다.
사이트를 넣은 이유는 너무 아이디, 도메인 만 추출을 하는 것 같아 새로운 것을 넣고 싶어서 사이트를 만들었다.
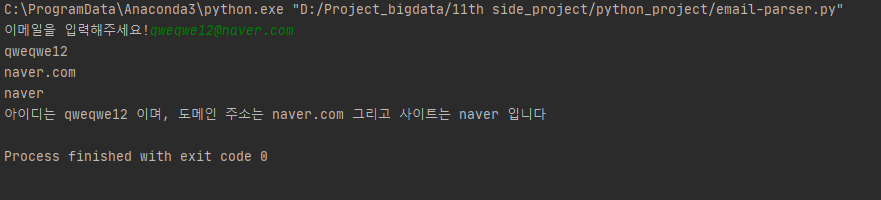
결과물은 아래와 같다.
'언어 > Python' 카테고리의 다른 글
| [pandas] : 판다스 전처리 할때 도움될만한 코드들 (0) | 2020.06.11 |
|---|---|
| Python side project 04 : binary search (이진 탐색) (0) | 2020.05.28 |
| Python side project 02 : Rolling Dice (주사위 게임) (0) | 2020.05.22 |
| Python side project 01 : Number guessing(숫자 맞추기 게임) (0) | 2020.05.21 |
| extends( ) VS appends( ) (0) | 2020.05.01 |