요점
빅데이터 기술과 데이터웨어 하우스의 다른점은
다수의 분산 시스템을 조합하여 확장성이 뛰어난 데이터 처리 구조를 만든다는 점이다..
1. 빅데이터의 기술
- 분산 시스템을 활용하여 데이터를 가공하는 구조
1) 데이터 파이프라인
- 데이터를 추출하여 특정 db 등 다른 저장 장치로 옮기는 기술,
- 수집 장소, 활용 목표에 따라 변화함,
- 간단한 구상에서 복잡하게 여러 개를 조합시켜야할 수도 있어야 함을 고려해야함
2) 데이터 수집
- 데이터 파이프라인의 시작,
- 데이터 전송에는 크게 두가지 방법이 존재 벌크형(bulk), 스트리밍 형(streaming) 으로 나뉨.
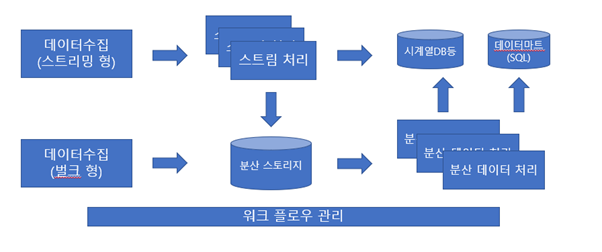
벌크형 : 이미 존재하는 데이터 추출, 데이터베이스와 서버 등에서 정기적으로 수집
스트리밍형 : 생성되는 데이터를 끊임없이 내보냄, 애플리케이션 및 임베디드 장비 등에서 수집
3) 스트림 처리
스트림 처리
- 빅데이터의 세계에서는 모바일 애플리케이션 등의 증가로 스트리밍 형 방법이 주류
- 실시간으로 처리가 됨, 시계열과 같이 사용되어 즉각적으로 상황 파악 가능,
- 장기적인 데이터 분석에는 적합하지 않음(데이터의 양이 지나치게 많아지기 때문)
4) 분산 스토리지(객체 스토리지, NOSQL)
- 대량의 데이터를 저장하고 처리하는데 적합
- 장기적인 데이터 분석을 위해 많이 쓰임, 배치 처리 형태(일괄 처리 형태)가 주로 쓰임
분산 스토리지 관련 참고 사이트
https://tech.kakao.com/2017/01/12/kage/
대규모 분산 스토리지(Kage)의 발전과정
Overview 대부분의 초기 스타트업은 컨텐츠를 저장할 저장소에 대한 별다른 고민을 하지 않습니다. 여유가 있다면 NAS 장비를 구매해서 사용하고, 아니라면 NFS와 RAID를 구성해서 사용하게 됩니다. �
tech.kakao.com
https://d2.naver.com/helloworld/258077
---> 분산 스토리지 공부에는 좋다
객체 스토리지
- 한 덩어리로 모인 데이터에 이름을 부여해서 파일로 저장, Amazon S3 대표적
- NOSQL도 분산 스토리지로 활용 가능. 많은 데이터를 읽고 쓰기에는 NOSQL 이 우수,
데이터 용량 늘리는데 제한이 없어 확장성 좋음
5) 분산 데이터 처리(쿼리 엔진, ETL 프로세스)
- 분산 스토리지에 저장된 데이터를 처리하는 방법,
- Map Reduce 가 주로 사용되는 부분,
- 데이터 처리에 많은 컴퓨터 자원이 필요
- 주 역할은 분석이 용이하도록 데이터를 가공해서 그 결과를 외부 데이터베이스에 저장하는 것
6) 빅데이터 SQL 로 집계하는 방법
- 쿼리 엔진 도입 : 분산 스토리지 상의 데이터를 SQL 로 집계, HIVE 가 대표적인 예
- ETL 프로세스 :
> 분산스토리지 -> 외부 DB에 저장,
> 데이터를 추출(Extract)하고, 그것을 가공(Transforam)한 다음, DW에 로드(Load) 하는 과정
7) 워크 플로우 관리
- 파이프 라인의 동작을 관리하는 것.
- 정해진 시각에 배치 처리 실행,
- 점차 파이프라인이 복잡해지면서, 효율적인 제어시스템과 에러 처리를 위한 기능을 만드는 것이 중요해짐
2. 데이터 웨어하우스와 데이터 마트 : 데이터 파이프라인 기본형

데이터 웨어하우스
대량의 데이터를 장기 보존하는 것에 최적화 됨, 정리된 데이터 한번에 전송에 뛰어나지만,
소량의 데이터를 자주 읽고 쓰는 것에는 부적합. 구축에는 ETL 도구 라는 전용 소프트 웨어 사용
- 데이터 소스 : 업무시스템을 위한 RDB, 로그 등을 저장하는 파일 서버
- ETL 프로세스 : DW에 보존된 로우데이터를 추출하고 필요에 따라 가공 후 DW 에 저장하는 흐름
업무에 있어서 중요한 데이터 처리에 사용, 자주 사용하는 것은 시스템 과부하를 초래.
데이터 마트
데이터 분석과 같은 목적에 사용하는 데이터만을 추출하여 보관하는 장소.
이를 데이터 마트를 구축한다고 함. BI 도구와 조합시키는 형태로 데이터 시각화에도 사용.
- 주의사항
> 테이블 설계를 제대로 정한 후에 데이터를 투입해야 함.
> BI 도구 사용시 시각화에 적합한 형태로 테이블 설계해야함.
> 테이블 설계와 ETL 프로세스가 중요함.
3. 데이터 레이크 : 데이터를 그대로 축적
모든 데이터를 원래 형태로 축적해두고 나중에 그것을 필요에 따라 가공하는 구조,
여러 곳에서 흘러들어오는 데이터를 축적하는 호수에 비유함
임의의 데이터를 저장할 수 있는 분산 스토리지가 데이터 레이크로 이용되고 있음.
주로 이용하는 포맷은 CSV, JSON 형식임
데이터 웨어하우스와의 차이점은 미가공의 원시 데이터를 그대로 저장소에 저장한다는 것임.

데이터 레이크 통해 데이터를 로우 데이터를 그대로 보존한 후, 언제 든지 꺼내서 데이터 마트를 통해 활용하도록
파이프라인의 체계가 바뀌고 있다.
(기존의 데이터 웨어하우스의 단점을 어느정도 해결)

'Book > 빅데이터를 지탱하는 기술' 카테고리의 다른 글
| 빅데이터의 탐색 2 - 3. 애드 혹 분석과 시각화 도구 (2) | 2020.06.23 |
|---|---|
| 빅데이터의 탐색 2 - 2. 열 지향 스토리지에 의한 고속화 (0) | 2020.06.21 |
| 빅데이터 기초지식 1 - 3. BI 도구와 모니터링 (0) | 2020.06.19 |
| 빅데이터 기초지식 1 - 2. 빅데이터 시대의 데이터 분석 기반 ( 2) (0) | 2020.06.17 |
| 빅데이터 기초지식 1 - 1. 빅데이터의 장착 (0) | 2020.06.13 |