처음 이 프로젝트를 시작할 때의 목표는 데이터 엔지니어가 하는 업무에 대해서
간단하게 이해해보자는 것이었다.
데이터 엔지니어는 데이터를 추출하고 (Extract) 가공하고 (Transform) 로드하는(Load)
전 프로세스를 설계하고 관리하는 직무이기 때문에
이 분야에 발을 담그게 된 이상, 이 업무 프로세스를 이해하는 것이 가장 중요하다고 판단했다.
위의 이유로 인해 거창한 것을 생각하기도 했으나.. 그것은 차츰 발전시켜 나가기로 하고.
우선 간단하게나마 내가 ETL 파이프라인 설계 구현에 초점을 맞추고 프로젝트를 진행하기로 했다.
1. 파이프라인의 전체적인 흐름
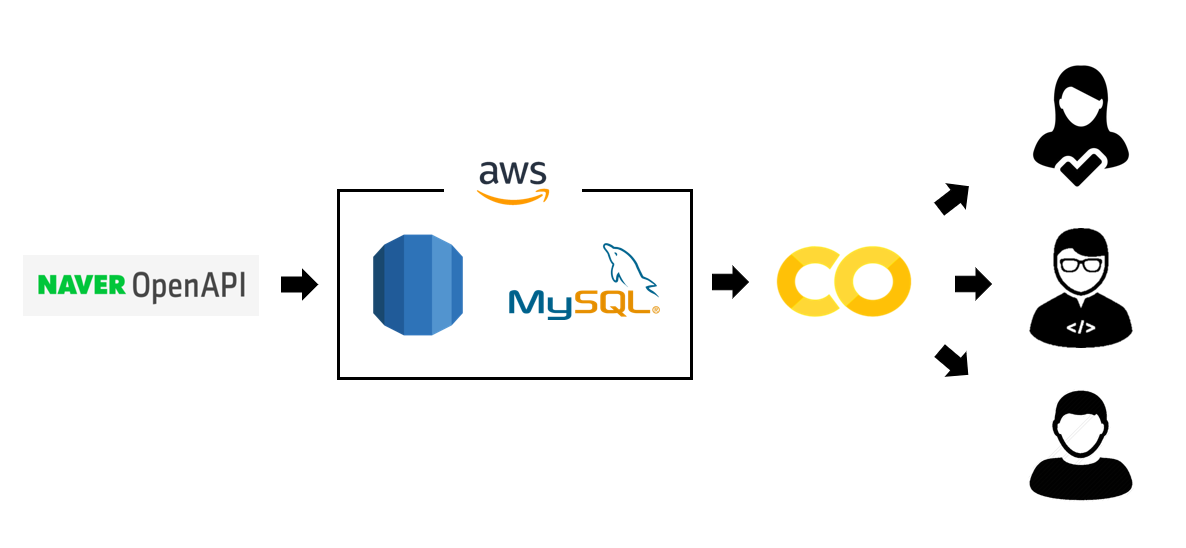
이번에 설계한 파이프라인의 전체적인 흐름은 위의 이미지와 같다.
데이터 쪽에 대규모로 투자할 여건이 되지 않는 스타트업에서 파이프라인을
설계 한다는 것을 가상의 상황으로 설정하고 진행했다.
1) 왜 네이버 OpenAPI 였는가
네이버를 택한 이유는 간단하다. 가상의 스타트업의 매출의 대부분이
네이버 shopping 에서 나오기 때문이다.
이번에 설정한 가상의 스타트업은 네이버 쇼핑에서 대부분의 매출을 내는 기업이다.
네이버에서 활동하는 유저들의 관심사와, 각 경쟁사들이 관심사 그리고 어떤 부분이
뜨고있고, 뜰 것이라는 것을 수시로 파악해야한다. 그래서 엔지니어인 나는 주요 데이터를 수집하는
곳을 네이버로 잡기로 결정했다.
2) 왜 AWS 인가?
이유는 간단하다. 데이터 설비에 큰 규모의 투자를 할 수 없기에 Serverless
서비스로 공간의 제약없이 성능 좋은 서비스를 사용할 수 있는 클라우드 서비스에 눈을 돌릴 수 밖에 없다.
azure 등의 다양한 경쟁사들이 있지만, 향후 데이터 수집 및 축적의 범위가
확장될 가능성과 다양한 서비스들과의 연계를 고려했을 때,
경쟁사들에 비해 안정적이고, 더 많은 서비스들과 연계할 수 있다는 장점을 지닌 AWS 를 선택했다.
3) 왜 MYSQL 인가?
실제로는 postgre 와 mysql 중에서 어떤 것을 사용할지 고민을 많이 했다.
mysql 이 많이 사용되고 있지만 최근에는 postgre도 많이 사용되어지고 있기 때문이다.

하지만, 수집되는 데이터를 고려했을 때, 정형 데이터만을 수집할 뿐이고,
비정형 데이터까지 수집하지는 않았다.
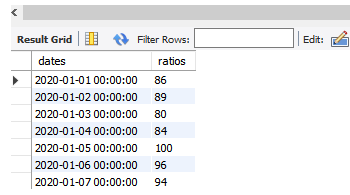
그리고 추후 정형데이터의 수집항목이 늘어날 수 도 있었다.
이 상황에서 mysql 을 선택하는 데에는 2가지 요인을 고려했다고 볼 수 있다.
1. 어떤 데이터를 수집할 것인지? ---> 정형 데이터만을 수집
2. 데이터 수집 항목이 늘어날 수도 있다! ---> 확장성이 있는 DB 선택!
이 두가지를 모두 만족하는 DB 는 MYSQL 이기에 MYSQL 을 선택했다.
그렇다고 Postgre 가 위 두개의 항목에서 안좋다는 것은 아니지만, mysql 이 2가지 측면에서 우위를
차지한다고 판단했다.
참고 링크
https://www.guru99.com/postgresql-vs-mysql-difference.html
PostgreSQL vs MySQL: What's the Difference?
1) What is PL SQL ? PL SQL is a procedural language which has interactive SQL, as well as...
www.guru99.com
4) 왜 Colab 인가?
colab 을 선택한 이유는 간단하다. 무료이고 구글이라는 접근성이 좋은 플랫폼에서 운영을 하고 있으며, 작업물을 공유하기 쉽기 때문이다.
aws 에도 물론 athena, spark 등의 분석 툴이 있다. 하지만, 이 도구들은 기본적으로 aws 의 사용법을 알아야 접근이 가능하며, 또 데이터를 추출하고 변형하여 분석을 하는데 좀 까다로운 면이 초보들에게는 없지않아 있다.
이러한 문제를 해결하기 위해서는 접근이 쉬워야 하고, 배우기 쉬운 언어로 운영되는 플랫폼을 찾아야 했는데, 그것이 colab 이었다. colab 은 구글에서 운영하기 때문에 접근하기가 매우 쉽고, 파이썬에서 판다스 기초만 배우면, 대부분의 작업이 커버가 가능했기에, colab 을 선택했다.
2. 프로젝트 소감
데이터 엔지니어 신입으로 근무하면서 사이드 프로젝트를 꾸준히 해야겠다는 결심을 하고 처음 시작한
프로젝트인지 감회가 새롭다. 처음에는 분석-머신러닝까지 해야될까 고민도 많았지만,
점차 프로젝트를 진행해가면서 고민들이 정리가 되고 명확해졌다..
데이터 엔지니어가 하는 업무에 대해서 파악하고 직접 체험해보자는 의미를 달성했다는 점에서
개인적으로는 큰 의의가 있다고 생각한다.
** 배운 점 **
2.1 데이터 엔지니어는 데이터의 성격이나, 수집 데이터의 종류에 따라 어떤 툴들을 선택할지, 어떤 프로세스를 짤지에 대한 고민이 필요한 직업이라는 점
2.2 회사의 규모와 상황 그리고 생산하는 데이터의 양과 질에 따라 파이프라인의 설계 및 운용 자체가 틀려지기에 각각의 상황에 맞는 파이프라인을 만들기 위해 주의해야한다.
'프로젝트, 인강 그리고 책 > Naver shopping Project' 카테고리의 다른 글
| Side Project 04( Final ). Colab 을 통해 최종적 파이프라인 구축하기x (0) | 2020.05.31 |
|---|---|
| Side Project 03. AWS 에 데이터 넣기 (3) | 2020.05.26 |
| Side Project 02. 네이버 쇼핑 데이터 수집 함수 만들기 (0) | 2020.05.26 |
| Side Project 01. 네이버 developer api 생성하기 (0) | 2020.05.26 |
| Side Project 00-1. 이번 사이드 프로젝트의 목표 (2) | 2020.05.26 |