1. 데이터 마트 구축의 파이프라인
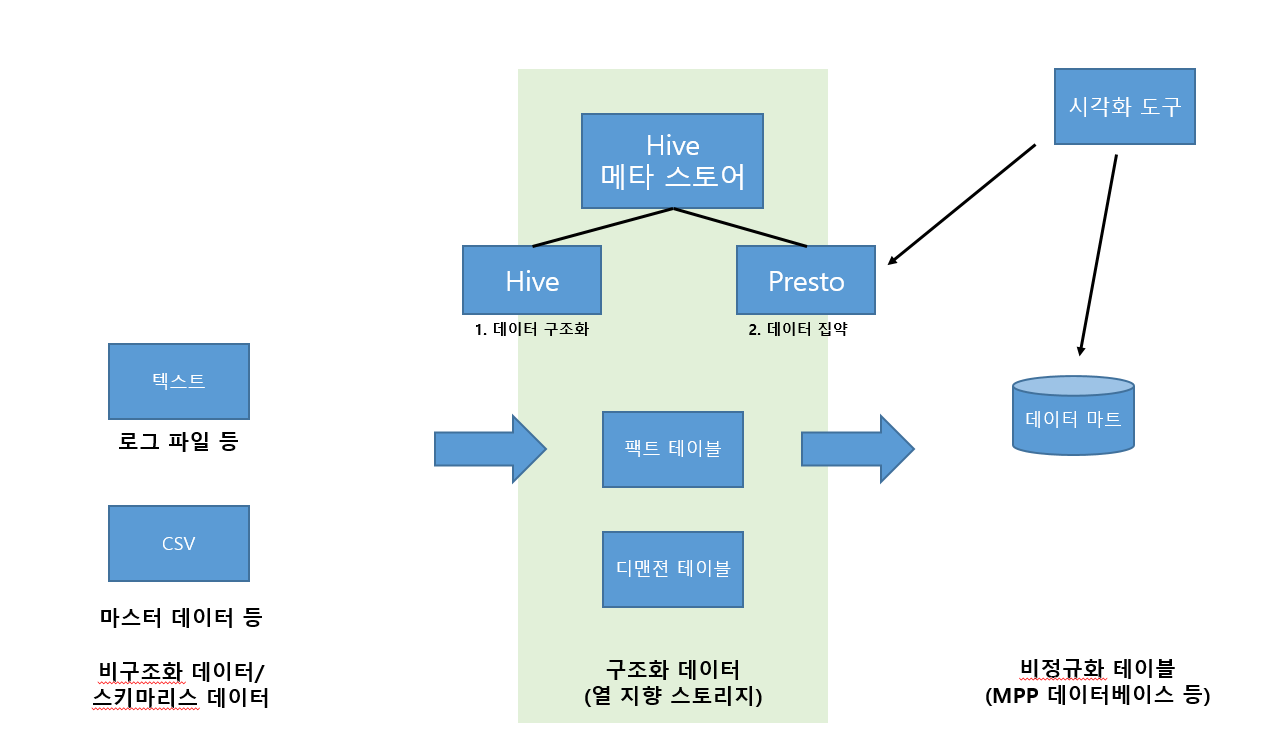
- 처음에 분산 스토리지에 저장된 데이터를 구조화하고 열 지향 스토리지 형식으로 저장한다.
- 이것은 다수의 텍스트 파일을 읽어 들여 가공하는 부하가 큰 처리가 되기 때문에 HIVE 를 이용한다.
- 그리고 완성한 구주화 데이터 데이터를 결합, 집계하고 비정규화 테이블로 데이터 마트에 써서 내보낸다.
- 열 지향 스토리지를 이용한 쿼리의 실행에는 Presto를 사용함으로써 실행시간 단축 가능
- Hive 에서 만든 각 테이블의 정보는 Hive 메타스토어라고 불리는 특별한 데이터베이스에 저장된다.
이것은 hive 뿐만 아니라 sql-on-hadoop의 쿼리엔진에서도 공통의 테이블 정보로 참고된다.
(메타스토어에 대한 정보)
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
2. Hive에 의한 구조화 데이터 작성
- 외부테이블 : Hive 의 외부에 있는 특정 파일을 참고해 마치 거기에 테이블이 존재하는 것처럼 읽어들이기 위해 지정
- 하이브를 비롯한 sql-on-hadoop 의 쿼리 엔진은 MPP 데이터베이스처럼 데이터를 내부로 가져오지 않아도
텍스트 파일을 그대로 집계할 수 있다.
- 데이터를 그 자리에서 바로 집계할 수 있는 성질은 특히 애드 훅 데이터를 분석하기에 유용하며, 시간을 들여
데이터를 전송하지 않고도 원하는 정보를 얻을 수 있음
- 대량의 출력을 수반하는 대규모 데이터 처리에 적합
1) 열 지향 스토리지로의 변환
- 하이브는 테이블마다 스토리지 형식을 지정할 수 있다.
- 하이브는 원래 데이터가 텍스트이든 스키마리스 데이터이든 간에 그것이 하이브에서 읽을 수 있는 형식이라면 무엇이든지
쿼리를 조금 고쳐 쓰는 것만으로도 어떤 테이블이라도 만들 수 있다.
아래는 대표적인 데이터 저장 양식이다.

[빅데이터] ORC와 Parquet 파일 저장 형식
빅데이터는 효율적인 데이터 저장을 위해 여러가지 저장 형식이 있습니다. 처음에는 TXT 형식으로 데이터를 저장하였지만, 데이터 저장공간과 처리 속도면에서 문제가 발생하면서 효율적인 처��
118k.tistory.com
2. 대화형 쿼리 엔진 Presto의 구조
- 작은 쿼리를 여러 번 실행하는 대화형 데이터 처리에는 적합하며, 쿼리 실행 지연을 감소시키는 것을 목적으로
개발된 것이 '대화형 쿼리 엔진' 이다.
- Presto 의특징
1) 플러그인 가능한 스토리지 : 하나의 쿼리 안에서 여러 데이터 소스에 연결 가능
2) CPU 처리의 최적화 : 읽기와 코드 실행 병렬 처리
3) 인 메모리 처리에 의한 고속화 : 쿼리 실행에는 가급적 대화형 쿼리 엔진 사용
4) 분산 결합과 브로드 캐스트 결합 : presto 는 기본적으로 분산결합을 실시, 같은 키를 갖는 데이터는 동일 노드에 모임
테이블이 충분히 작은 경우에는 '브로드캐스트 결합'을 사용하여 처리속도를 크게 고속화할 수 있음
5) 열 지향 스토리지 집계 : Presto에 의한 고속집계, 열 지향 스토리지의 집계를 매우 빠르게 실행할 수 있음
3. 데이터 분석의 프레임 워크 선택하기
1) MPP 데이터 베이스
- 완성한 비정규화 테이블의 고속 집계에 적합
- 스토리지 및 계산 노드가 일체화되어 있어 처음에 ETL 프로세스 등으로 데이터를 가져오는 절차가 필요.
- 위 부분 완성시 SQL 만으로도 데이터를 집계할 수 있음
- 시각화를 위한 데이터 마트에는 유력한 대안
2) Hive
- 데이터 양에 좌우되지 않는 쿼리 엔진
- 대규모 배치 처리를 꾸준히 실행함
- 텍스트 데이터를 가공하거나 열 지향 스토리지를 만드는 등 무거운 처리에는 hive 를 실행하는 것이 적합
3) Presto
- 속도 중시 & 대화식으로 특화된 쿼리 엔진
- 속도로 인해 다양한 것은 희생함(Hive와 정반대)
- 오류가 떠서 다시 실행해야 되지만, 빠른 실행속도로 인해 오류가 발생하면 다시 반복해서 사용함
- 대화식 쿼리의 실행에 특화되어 있어 텍스트 처리가 중심이 되는 ETL 프로세스 및 데이터 구조화에는 적합하지 않음
- 단시간에 대량의 리소스를 소비하여, 너무 무리하게 사용을 할 경우, 다른 쿼리를 실행할 수 없음
'프로젝트, 인강 그리고 책 > 빅데이터를 지탱하는 기술' 카테고리의 다른 글
| 빅데이터의 탐색 4-1. 벌크형과 스트리밍 형의 데이터 수집 (0) | 2020.12.03 |
|---|---|
| 빅데이터의 탐색 2 - 3. 애드 혹 분석과 시각화 도구 (2) | 2020.06.23 |
| 빅데이터의 탐색 2 - 2. 열 지향 스토리지에 의한 고속화 (0) | 2020.06.21 |
| 빅데이터 기초지식 1 - 3. BI 도구와 모니터링 (0) | 2020.06.19 |
| 빅데이터 기초지식 1 - 2. 빅데이터 시대의 데이터 분석 기반 ( 2) (0) | 2020.06.17 |