현재 진행하고 있는 프로젝트는 페스트 캠퍼스에서 듣고 있는 인강인
한승수 강사님의 데이터 엔지니어링 강의를 다시한번 복습하고
내재화하고자 진행하는 프로젝트인 점 참고바란다.

이번에는 저번에 이어서 S3 에 데이터를 저장함으로써
' 데이터 레이크 '
를 만들었다.
S3 는 Simple Storage Service 의 약자로써 개발자가 원하는 양의 데이터를
쉽게 저장하고 검색할 수 있도록 도와주는 서비스이며, 심플한 웹 인터페이스를
통하여 어디서든 스토리지에 엑세스 할 수 있다는 장점이 있다.
https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/dev/Welcome.html
Amazon S3이란 무엇입니까? - Amazon Simple Storage Service
Amazon S3이란 무엇입니까? Amazon Simple Storage Service는 인터넷용 스토리지 서비스입니다. 이 서비스는 개발자가 더 쉽게 웹 규모 컴퓨팅 작업을 수행할 수 있도록 설계되었습니다. Amazon S3에서 제공하
docs.aws.amazon.com
하지만, 이 프로젝트의 경우 S3 는 API를 통해서 가져온
데이터들을 저장하는 데이터 레이크의 용도로 사용할 계획이다.
즉, S3 에 Spotify 의 데이터를 저장하고 Athena 와 같은 분석 툴들과
챗봇의 기반 DB 가 되는 DynamoDB 가 언제든지 필요한 데이터를
추출하여 사용할 수 있는 기반이 되는 스토리지의 역할을
S3 가 한다고 보면 되겠다.
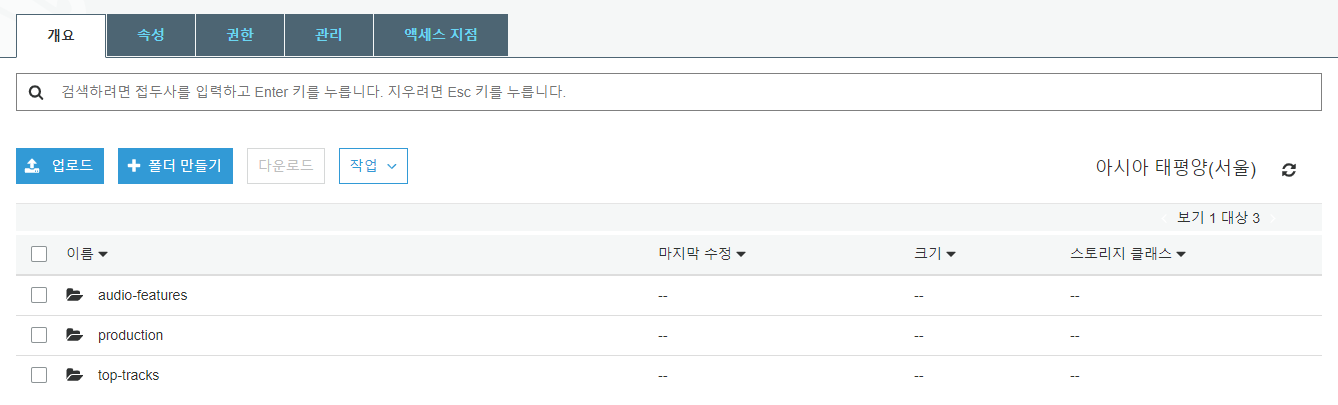

S3 에 위와 같은 형식으로 데이터들을 저장해두었으며,
향후 S3는 데이터 분석을 위해 AWS 의 Athena 와
챗봇의 메인 DB 인 DynamoDB 에 의해 데이터 데이터가 주로 추출되는
데이터 레이크의 역할을 할 것이다.
지금까지 구축한 파이프라인은 아래와 같다

향후 Athena 를 통해 S3 의 데이터를 추출하여 분석툴을 통해 작업하는 파이프라인과
다이나모 DB 를 통하여 챗봇을 구현하는 파이프 라인으로
나뉠 것이다.
이번 프로젝트에서는 분석 툴까지만 구현을 하고, 챗봇은 구현하지는 않을 예정이다.
이번 목적은 분석과, 서비스 구현을 위한 파이프라인을 구현하는데 있기 때문이다.
챗봇의 경우에는 데이터가 축적되면서 확장될 가능성이 매우 높기 때문에
추후 챗봇을 구현할 경우를 대비하여 DynamoDB 를 사용하였다.
그리고 내부에서 사용될 분석 툴은 대용량의 데이터도 원활하게
맵리듀스하여 분석할 수 있는 스파크와 스파크의 내용을 쿼리로 쉽게 꺼내
분석할 수 있는 제플린을 사용했다.
'프로젝트, 인강 그리고 책 > Spotify Project' 카테고리의 다른 글
| Spotify Project 07. Spotify - 분석 파이프라인 구축(프로젝트 완료) (0) | 2020.07.10 |
|---|---|
| Spotify Project 05. Spotify - AWS Data 수집 프로세스 구축 (0) | 2020.06.28 |
| Spotify Project 04. Spotify 에서 artists , album 정보 가져오기 (0) | 2020.06.14 |
| Spotify Project 03. 프로젝트 진행위한 API 관련 사항 (0) | 2020.06.09 |
| Spotify Project 02. aws 사용하기에 앞서 설정해두어야 할 것(aws cli) (0) | 2020.06.07 |